Character encoding / 代码页 / 内码表 / 字符编码
ascii
计算机诞生于美国,只需要考虑他们那边的编码即可
因为拉丁字符很少,加上一些控制命令,只用了 7 位,即
eascii (Extended)
在 ascii 的基础上把最前一位二进制利用了起来,拓展 askii 码诞生;
gbk
原理是用两位二进制数表示一个中文汉字,最多可以表示 个字符,结构为
中国标准,这个字符集并没有得到世界统一,所以浏览别国电脑编码的文件,会有乱码的问题;
unicode
unicode 是规定了一个巨大的字符集,最多可以表示
实际几乎没有用到最前一位,表示范围是 0×00000 到 0x10FFFF,即最多可以表示
utf-8
一种变长表示方式,使用 1~4 个字节表示一个字符,以开头的特殊序列区分字符,映射关系如下:
| Unicode 编码 (16 进制) | UTF-8 字节流 (二进制) |
|---|---|
000000 – 00007F | 0xxxxxxx |
000080 – 0007FF | 110xxxxx 10xxxxxx |
000800 – 00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
010000 – 10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
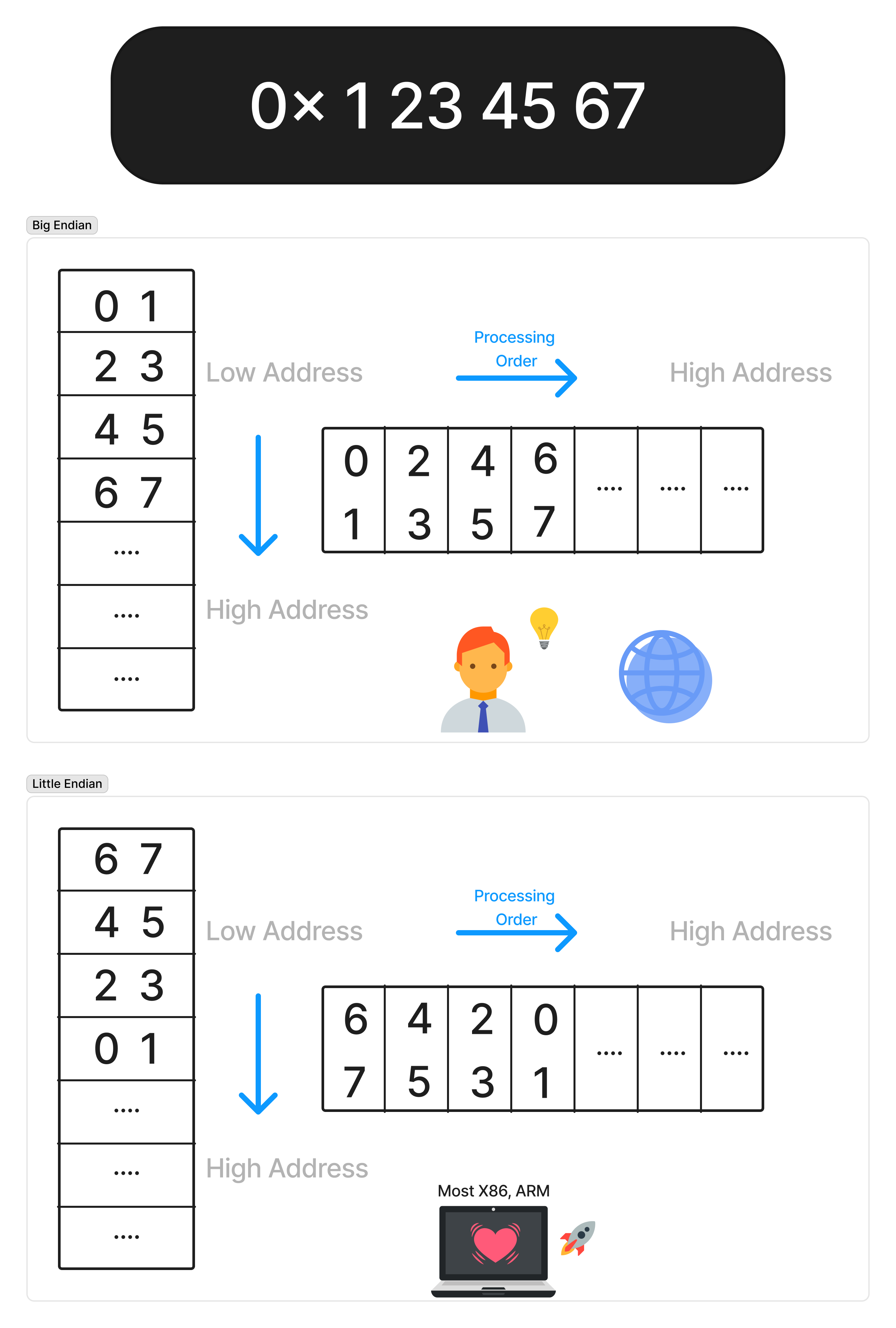
Endian 大小端 / 字节序 / 端序 / 尾序
小人国为水煮蛋该从大的一端 (Big-End) 剥开还是小的一端 (Little-End) 剥开而争论,争论的双方分别被称为 ” 大端派 (Big-End·ians)” 和 ” 小端派 (Little-Endians)” Gulliver’s Travels
不同的处理器架构字节存放顺序不同, 如 intel 全小端, amd 大小端都支持;
小端 / 小尾序 / Little-endian
低位字节在前 (地址较小处),高位字节在后 (地址较大处)
大端 / 大尾序 / Big-endian
高位字节在前,低位字节在后

So to be sure about the ARM endianness, you need to refer to the reference manual from the manufacturer. via: Is ARM big endian or little endian?
BOM(byte-order mark)
unicode 编码中表示字节编码方式的头,区分如下:
| UTF 编码 | Byte Order Mark |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
因为 BOM 一开始就是给 UTF-16 和 UTF-32 设计的,UTF-8 不参与这个游戏,所以其在大小端的机器上表示方式都一样,如字符 你 U+4F60
# UTF-8
0xE4 0xBD 0xA0
# UTF-16
0x4F 0x60 # BE
0x60 0x4F # LE
# UTF-32
0x00 0x00 0x4F 0x60 # BE
0x60 0x4F 0x00 0x00 # LE添加 BOM 是微软的习惯,所以 UTF-8 就分有无 BOM 的版本,但实际 BOM 屁用没有;
Code Page
I was trouble in the CP problem within a whole afternoon(20200703) in that java GUI/language output only support the sys language(GBK), meanwhile Window family version isn’t support the English-System. Oh only damn it. So I catch some Code Page to switch.
Code page is a character encoding and as such it is a specific association of a set of printable characters and control characters with unique numbers.
- IBM code pages
- DOS code pages
- IBM AIX code pages
- IBM OS/2 code pages
- Windows emulation code pages
- Macintosh emulation code pages
- Adobe emulation code pages
- HP emulation code pages
- DEC emulation code pages
- IBM Unicode code pages
- Windows code page
- DBCS code pages
- MS-DOS code pages
- Macintosh emulation code pages
- Various other Microsoft code pages
- Microsoft Unicode code pages
Links
- https://gist.github.com/fanfeilong/844ad0c2e2654cfd4c7e
- EASCII
- ISO 8859
- ISO 8859-n(n=1,2,3,…,11,13,…,16)
- Latin-1 == ISO8859-1
- GB2312 id: 6d652964-9186-407d-bbae-464bee0b36a1
- GBK(Chinese Internal Code Specification)
- > ((6d652964-9186-407d-bbae-464bee0b36a1))
- BIG5 (small conflict with GB2312)
- GB18030
- > ((6d652964-9186-407d-bbae-464bee0b36a1))
- Unicode (NOT Compatible with GBXXX)
- UCS2
- UTF-16 (Extend UCS2)
- UCS4
- UTF-32 (Currently a subset of UCS4, But ability to encode more unicode characters)
- UTF-8
- BOM
- No BOM
- https://zi-hi.com/
- http://lovecn.github.io/utf8.html
- ISO/IEC 8859 - Wikipedia; ISO/IEC 8859 - 維基百科,自由的百科全書
- ~很多网站源码都是分为-GBK-和-UTF-8-版-为什么要同时开发两种
- ~为何微软不把-Windows-的默认字符集设置成-UTF-8
- ~在-Windows-下键入-Enter-键-是在键盘缓冲区中存入-‘n’-还是-‘r”n’-两个
- https://en.wikipedia.org/wiki/Character_encoding
- ~理解字节序
- https://en.wikipedia.org/wiki/Code_page